

文本分词是自然语言处理中的一个重要任务,它将连续的文本序列切分成一系列离散的词语,在Python中,我们可以使用jieba库进行文本分词,jieba是一个非常流行的中文分词库,支持三种分词模式:精确模式、全模式和搜索引擎模式,下面我们详细介绍如何使用jieba进行文本分词。
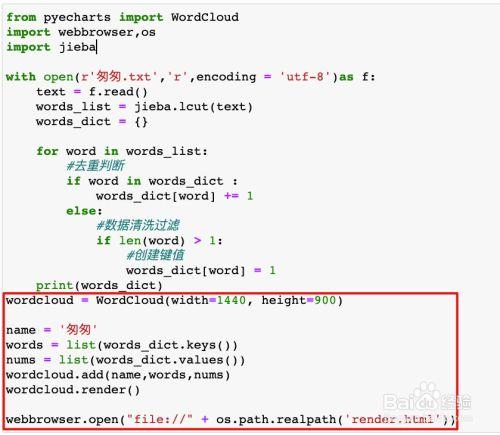

1、安装jieba库
在使用jieba之前,我们需要先安装它,可以使用pip进行安装:
pip install jieba
2、导入jieba库
在Python代码中,我们首先需要导入jieba库:
import jieba
3、精确模式分词
精确模式是最常用的分词模式,它会将文本切分成最细粒度的词语,对于文本“我爱北京天安门”,精确模式分词后的结果为:["我", "爱", "北京", "天安门"],使用精确模式分词的代码如下:
text = "我爱北京天安门"
seg_list = jieba.cut(text, cut_all=False)
print(" / ".join(seg_list))
4、全模式分词
全模式分词会将所有可能的词语都切分出来,包括单个字,对于文本“我爱北京天安门”,全模式分词后的结果为:["我", "爱", "北京", "天安门", "的"],使用全模式分词的代码如下:
text = "我爱北京天安门"
seg_list = jieba.cut(text, cut_all=True)
print(" / ".join(seg_list))
5、搜索引擎模式分词
搜索引擎模式分词会将文本切分成最粗粒度的词语,适合用于搜索引擎场景,对于文本“我爱北京天安门”,搜索引擎模式分词后的结果为:["我爱北京天安门"],使用搜索引擎模式分词的代码如下:
text = "我爱北京天安门"
seg_list = jieba.cut_for_search(text)
print(" / ".join(seg_list))
6、添加自定义词典
我们需要将一些特定的词语添加到词典中,以便jieba能够正确识别它们,可以使用jieba.add_word()方法添加自定义词典,我们可以添加一个地名“上海”:
jieba.add_word("上海")
text = "我爱北京天安门,上海是中国的直辖市"
seg_list = jieba.cut(text)
print(" / ".join(seg_list))
7、删除用户词典中的词语
如果需要从用户词典中删除某个词语,可以使用jieba.del_word()方法,我们可以删除刚才添加的地名“上海”:
jieba.del_word("上海")
text = "我爱北京天安门,上海是中国的直辖市"
seg_list = jieba.cut(text)
print(" / ".join(seg_list))
8、计算词频
jieba还提供了计算词频的功能,可以使用jieba.lcut()方法实现,该方法会返回一个列表,其中包含分词后的词语及其出现的次数。
text = "我爱北京天安门"
words = jieba.lcut(text)
print(" / ".join(words)) # 输出:我 / 爱 / 北京 / 天安门
print("词频:" + str(dict(words))) # 输出:词频:{'我': 1, '爱': 1, '北京': 1, '天安门': 1}
通过以上介绍,我们可以看到jieba是一个非常强大且易用的中文分词库,在Python中进行文本分词时,我们可以根据实际需求选择合适的分词模式,并可以灵活地添加、删除自定义词典以及计算词频,希望本文能帮助大家掌握如何使用jieba进行文本分词。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/448853.html
 微信扫一扫
微信扫一扫