

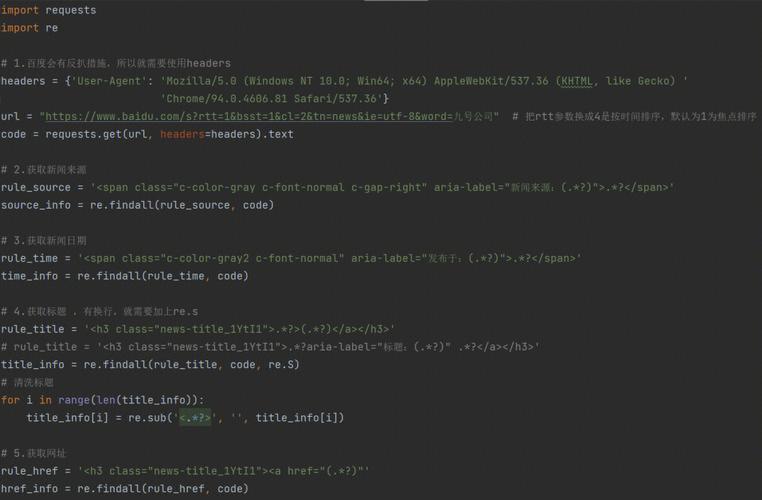
要爬取百度文库的内容,可以使用Python的第三方库requests和BeautifulSoup,以下是详细的步骤:

(图片来源网络,侵删)
1、安装所需库:
pip install requests pip install beautifulsoup4
2、导入所需库:
import requests from bs4 import BeautifulSoup
3、获取文库页面内容:
def get_wk_content(url):
headers = {
'UserAgent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
4、解析文库页面内容:
def parse_wk_content(html):
soup = BeautifulSoup(html, 'html.parser')
content = []
for item in soup.find_all('div', class_='iefix'):
content.append(item.get_text())
return content
5、主函数:
def main():
url = 'https://wenku.baidu.com/view/your_doc_id.html' # 替换为你的文库文档ID
html = get_wk_content(url)
if html:
content = parse_wk_content(html)
for i, text in enumerate(content):
print(f'第{i + 1}段:')
print(text)
print('' * 50)
else:
print('获取文库页面失败')
if __name__ == '__main__':
main()
注意:请将your_doc_id替换为你要爬取的文库文档ID。
这个程序会输出文库文档的每一段内容,如果需要进一步处理,可以对parse_wk_content函数进行修改。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/453694.html
 微信扫一扫
微信扫一扫