

大数据计算MaxCompute中的数据更新机制与Tunnel API
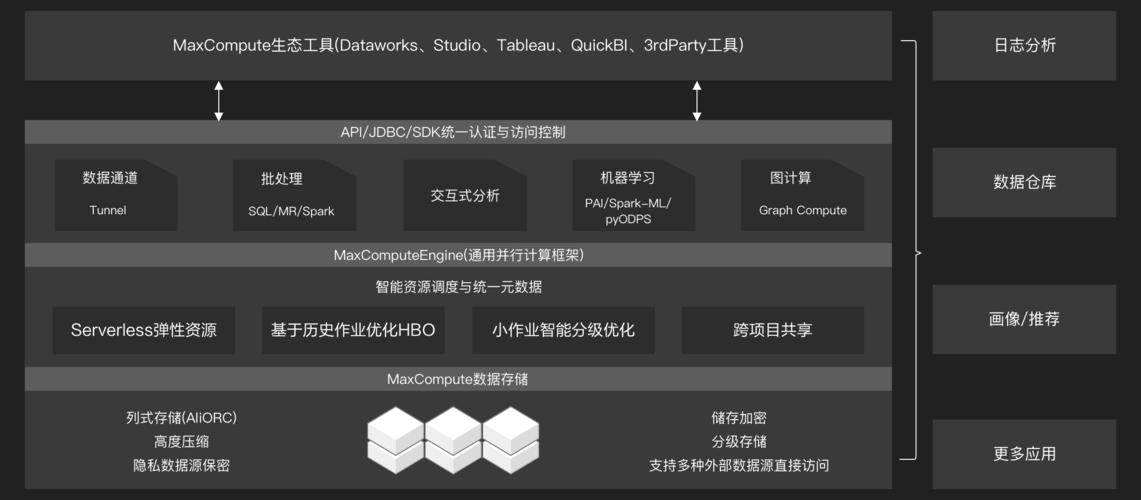

1. MaxCompute简介
MaxCompute(原名ODPS,即Open Data Processing Service)是阿里云提供的一种大数据计算服务,它可以处理PB级别的海量数据,支持多种数据处理模型如批处理、流处理、机器学习等,MaxCompute底层基于分布式存储和计算框架,对外提供了SQL和MapReduce等编程接口,方便用户进行大规模数据分析和挖掘。
2. Tunnel API介绍
Tunnel API是MaxCompute提供的一组API集合,用于实现数据同步(近实时)和批量导入导出等功能,通过Tunnel服务,用户可以将数据从不同的数据源传输到MaxCompute,或者将MaxCompute的数据传输到其他系统,Tunnel服务支持多种数据源,包括但不限于:
数据库:如MySQL、Oracle等
文件:如OSS(Object Storage Service)、HDFS等
消息队列:如Kafka、RabbitMQ等
3. 数据更新机制
在MaxCompute中,数据的更新通常是指替换或插入新数据到现有的表中,更新操作可以通过以下几种方式触发:
直接写入:用户可以直接将数据写入到表中,如果表已存在相同主键的数据,则进行更新;否则,进行插入。
外部数据源同步:通过Tunnel服务同步外部数据源的变化到MaxCompute表中。
作业调度:通过调度作业周期性地执行数据更新任务。
4. Tunnel API如何知道数据是该update?
当使用Tunnel服务同步数据时,Tunnel API会根据数据源的变更来识别是否需要更新MaxCompute中的数据,具体来说,Tunnel服务会监听数据源的变化,
数据库的变更:通过binlog或触发器等方式捕获数据变化。
文件的变化:监控文件系统的变更事件。
消息队列的消息:消费消息队列中的数据变更事件。
一旦检测到数据变化,Tunnel服务就会将这些变化应用到MaxCompute的目标表中,这个过程包括:
增量更新:只同步发生变化的数据。
全量更新:重新同步整个数据集。
Tunnel服务还支持定义数据同步规则,比如字段映射、数据过滤、转换等,以便更加灵活地处理数据同步任务。
5. 技术教学:配置Tunnel服务进行数据更新
以下是配置Tunnel服务进行数据更新的基本步骤:
1、创建Tunnel任务:
登录MaxCompute控制台。
在Tunnel服务页面创建一个新的Tunnel任务。
2、配置数据源:
根据数据源类型选择相应的连接器。
填写数据源的相关配置信息,如数据库地址、用户名密码等。
3、配置目标表:
选择或创建MaxCompute的目标表。
定义字段映射关系,确保数据源的字段与目标表的字段对应。
4、设置同步规则:
根据需求选择增量更新还是全量更新。
定义数据过滤条件,只同步需要更新的数据。
5、启动Tunnel任务:
保存并启动Tunnel任务。
监控任务运行状态,确保数据正确同步到MaxCompute。
6、验证数据更新:
查询目标表,检查数据是否正确更新。
如果有必要,可以调整Tunnel任务的配置以优化性能。
归纳来说,Tunnel API通过监听数据源的变化并根据同步规则来判断数据是否需要在MaxCompute中进行更新,配置Tunnel服务需要明确数据源、目标表以及同步规则,确保数据能够准确且及时地更新到MaxCompute中。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/528965.html
 微信扫一扫
微信扫一扫